Understanding Vanilla RNN

Machine Learning. Deep Learning. Representational Learning.
Three distinct concepts, three different mathematics, yet one phenomenon binds them: the phenomenon of LEARNING.
What Does Learning Actually Mean?
Learning refers to the process of finding parameters (popularly weights and bias) that provides optimized results, i.e., minimizes the loss function of the given model.
Loss is the difference between the value predicted by model and the actual value present.
The Foundation: Data
The basis of learning, or the raw material, is the data that we use during training a model. As we are aware, the data can be of different categories altogether:
- Spatial data
- Temporal data
- Independent numerical data
Specialized Neural Network Architectures
Different model architectures are invented to generalize a category of data. Neural Networks, or ANNs (Artificial Neural Networks), work well with independent data, either numerical or categorical.
However, these ANNs cannot be trusted with specialized categories of data such as:
-
Spatial Data: Data that contains information about the location, shape, and spatial relationship of objects in physical space
-
Temporal Data: Data that contains information about objects with temporal dependency between them; in other words, data that is indexed by time, where the sequence or timing of observations are essential to interpretation and prediction
Architecture Selection by Data Type
For these specialized categories of inputs, we use specialized classes of neural network architecture:
CNN (Convolutional Neural Networks)
- Data Type: Spatial data
- Common Application: Image-based tasks
RNN (Recurrent Neural Networks)
- Data Type: Temporal data
- Common Application: Text-based tasks
Note: Image and text here are just popular applications of CNN and RNN; however, they indeed have wider applications.
We'll talk about RNN in this article.
Vanilla RNN Architecture and Backpropagation through time
A vanilla RNN is a uni-directional RNN that captures sequential information from left-right or right-left. Let us understand the architecture with the help of diagrams below.
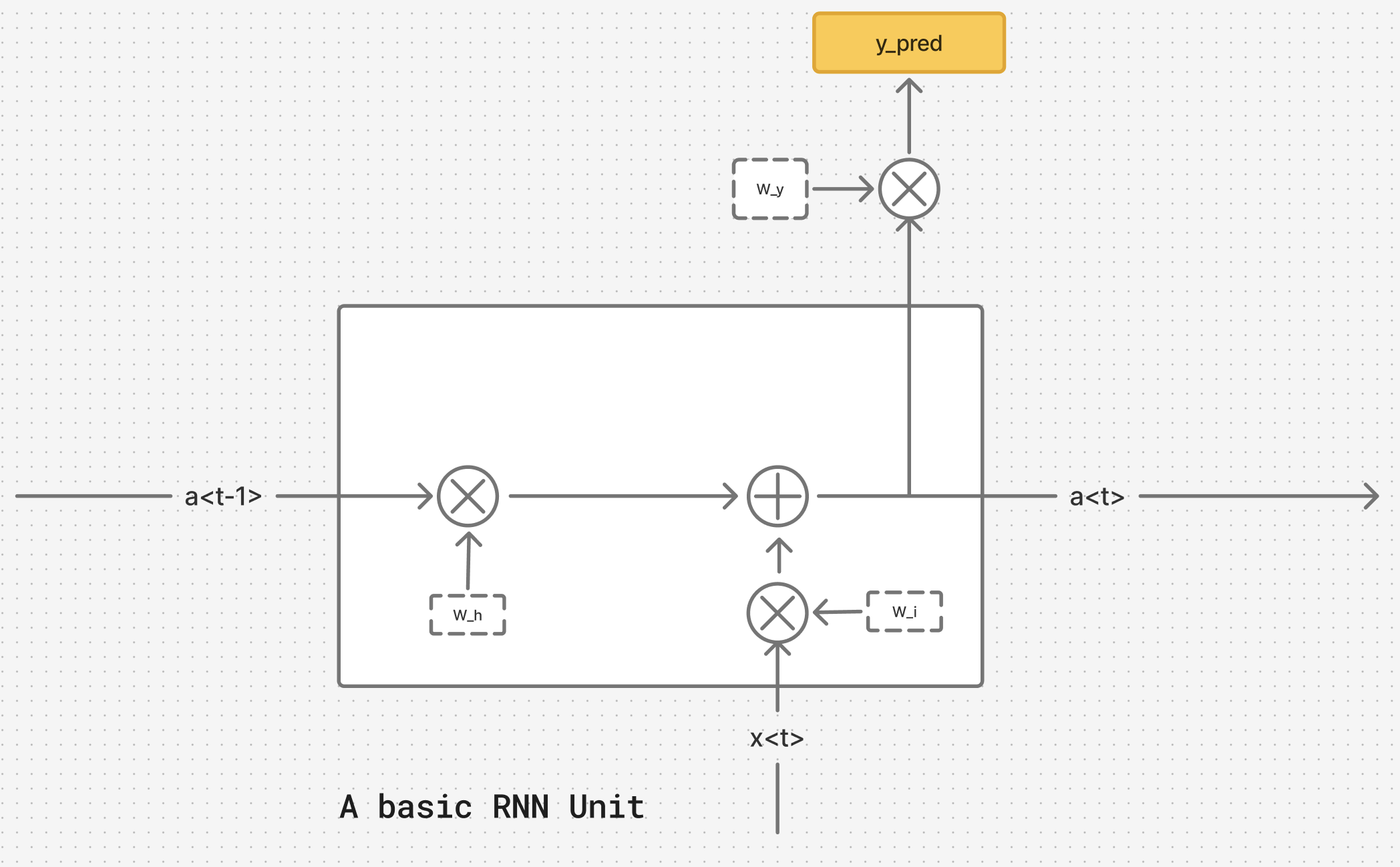
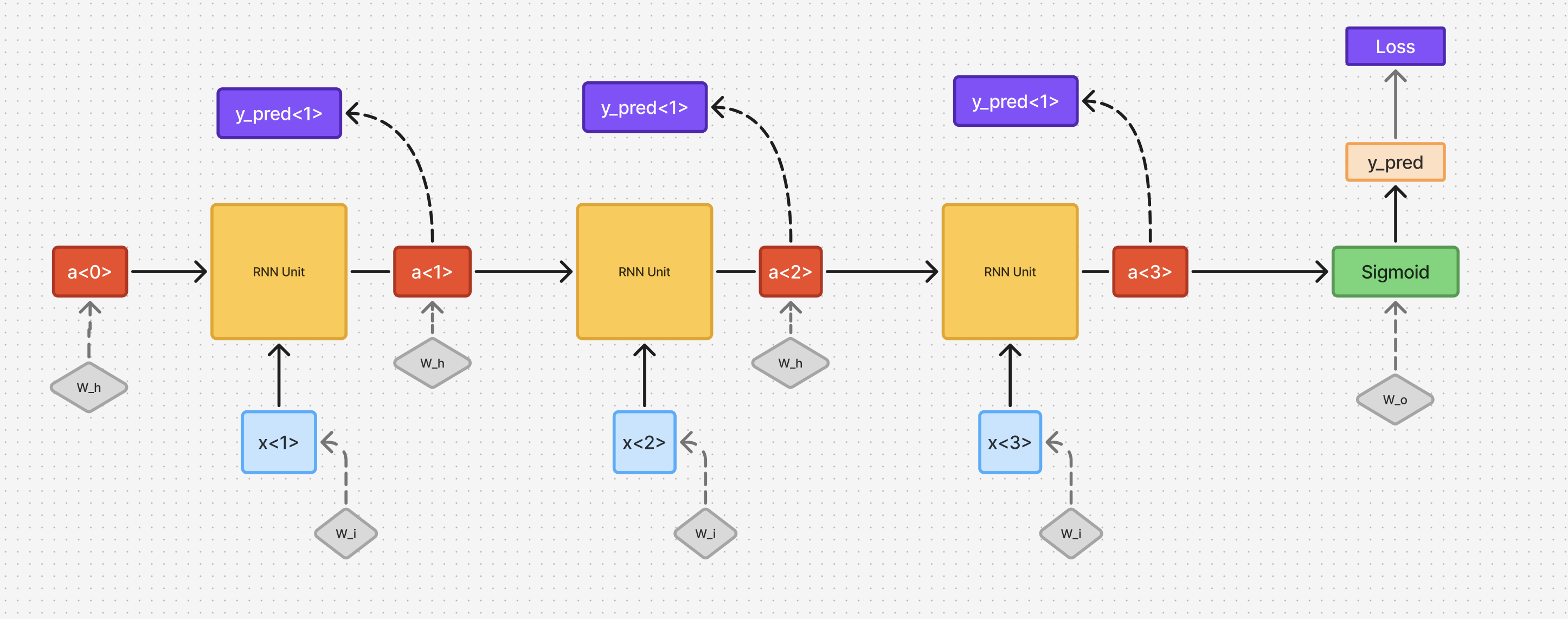
From the above diagram, we re-iterate the presence of two inputs for each unit: static & temporal. In this architecture, we are working on a training example where the entire sequence is already available, and there is no need to generate the next-in-sequence datapoint. As a result, is not dependent on previous unit , as is in the case of sampling, where the output of previous unit is used as an input for the subsequent unit .
Mathematical Interpretation
A. Forward Propagation
Assuming no of inputs = Assuming no of inputs , we compute two components:
- Hidden state value:
- Output unit:
For given parameters, , & corresponding to Hidden state and & corresponding to :
For every time-step 't':
We can further simplify equation (1) corresponding to by compressing two parameters & into :
here the matrices & are stacked horizontally
If & , then
Using in :
Now,
here matrices & are vertically stacked
Finally:
B. Backpropagation Through Time
- Similar to ANN, the real learning happens in backpropagation, where we minimize the loss function by finding optimum values for the given parameters.
- We use gradient descent to reach the optimal values
- To simplify the understanding, let us assume there is only one output for the network, that is present at timestep .
- The loss function as defined below depends only on one value of , instead of at every time step
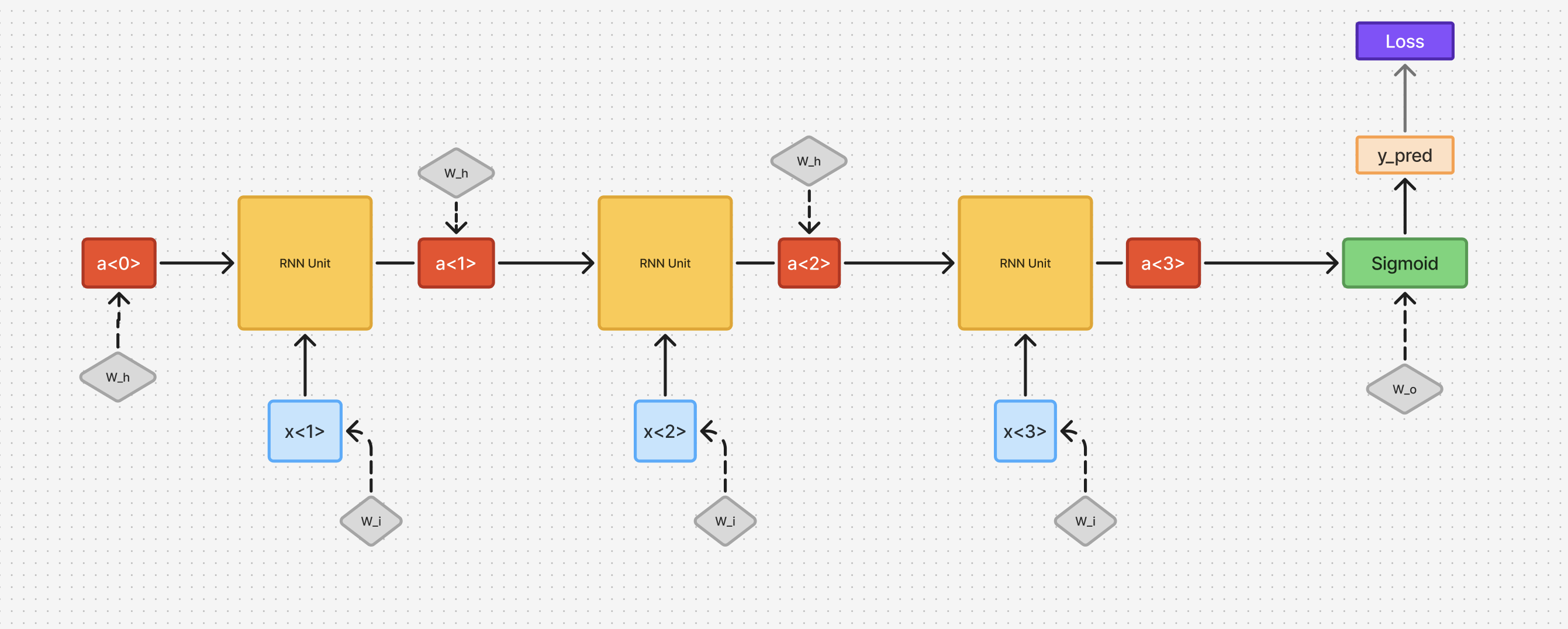
We use cross entropy loss:
In case we predict an outcome at every timestep:
Following are the parameters we will optimize:
- : weights for hidden units
- : weights for input units
- : weights for output unit
Applying gradient descent for learning rate :
Our goal is to find , , values to calculate optimal , ,
I. Calculating
The given mind map shows the dependency mapping of functions, which helps to visualise the chain rule to calculate the gradient:
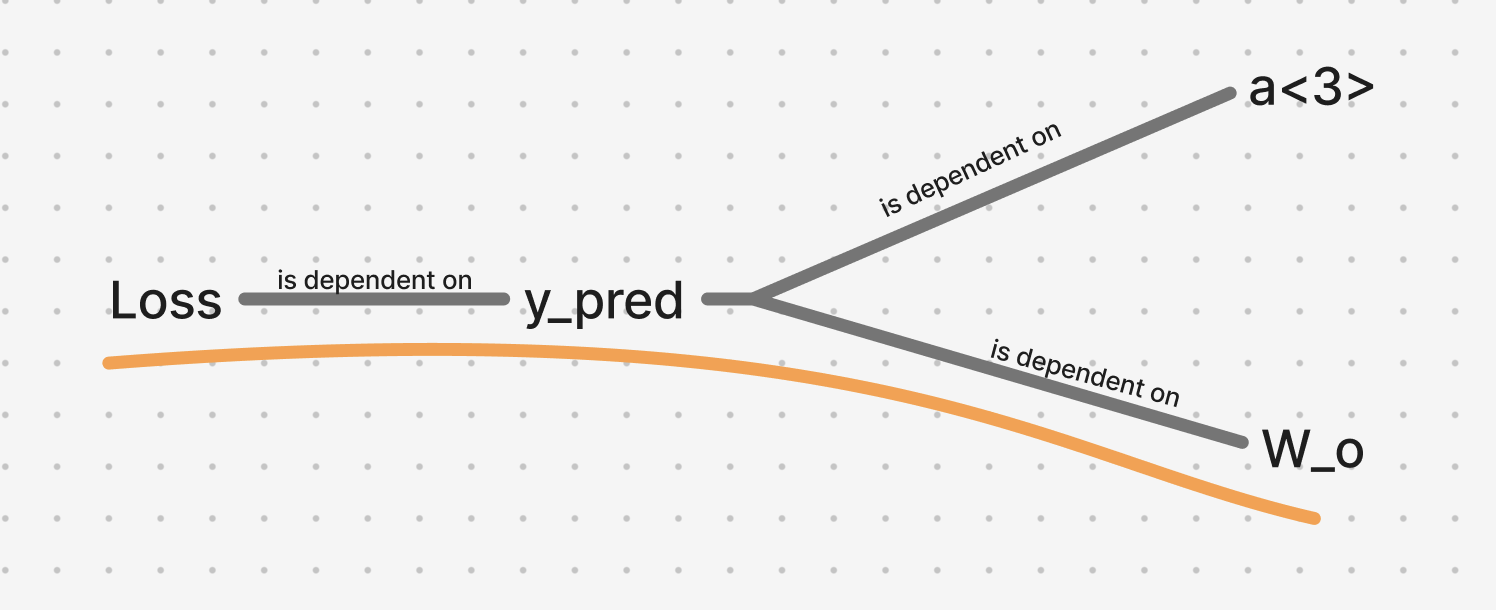 From the above mapping we can calculate:
From the above mapping we can calculate:
using chain rule
II. Calculating
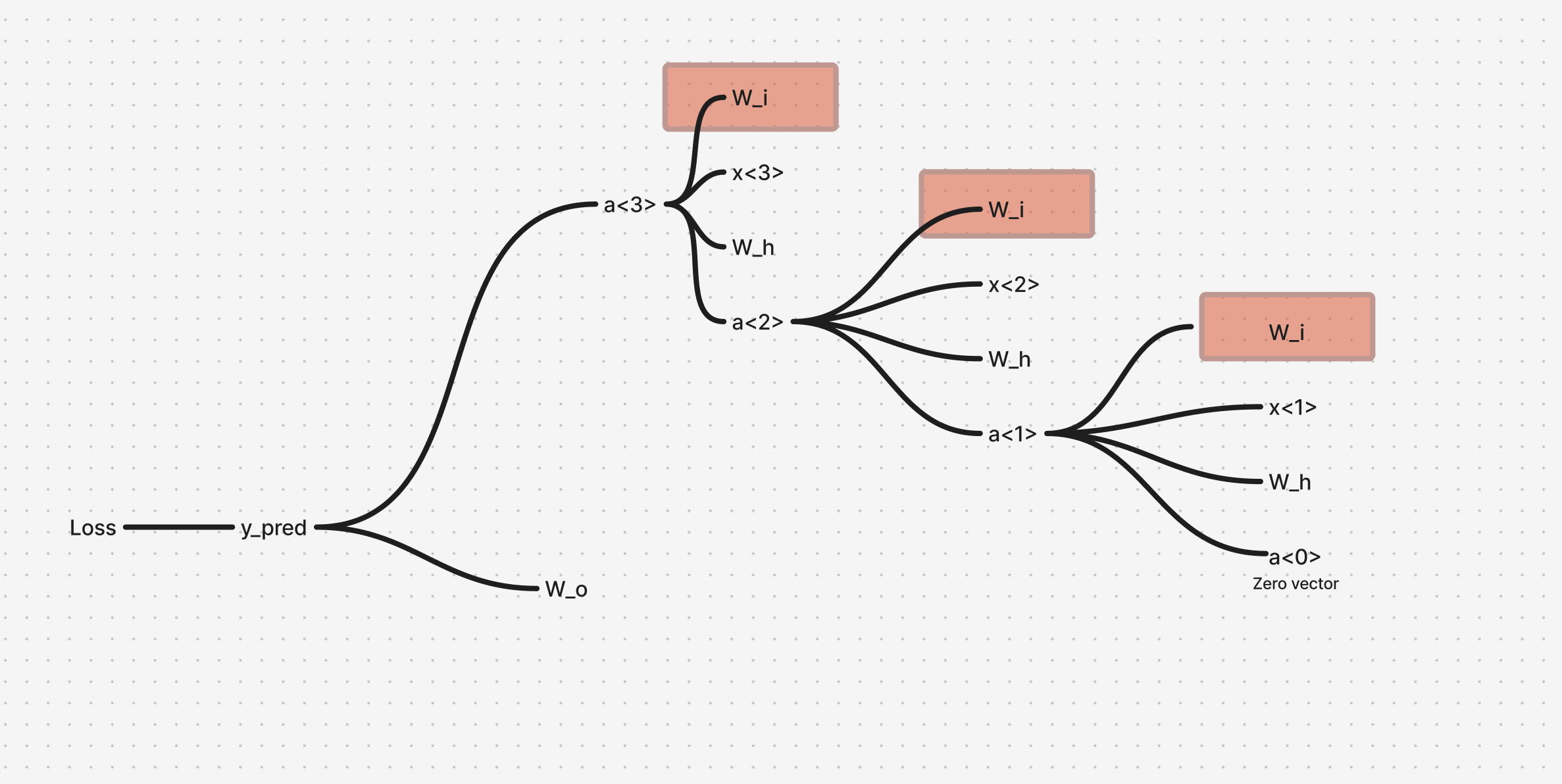
From the above dependency mapping, we have 3 simultaneous dependencies that occur as we move back in timestep from to , which can simply be added together, after calculating the gradient for each timestep.
For timestep 3:
For timestep 2:
For timestep 1:
Combining all three:
Generalizing this for timesteps :
III. Calculating
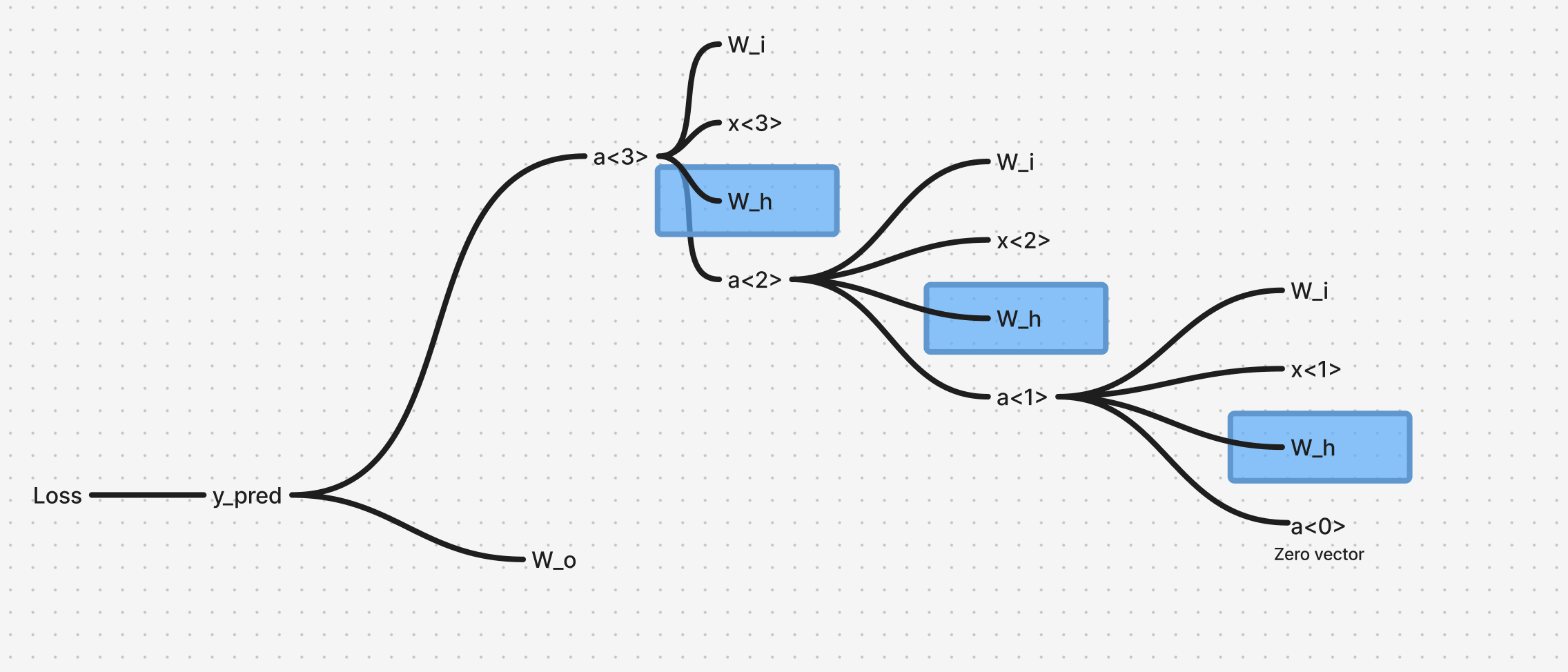 Using the same dependency mapping from the previous calculation, we again have multiple simultaneous dependencies as we go down the timesteps.
Using the same dependency mapping from the previous calculation, we again have multiple simultaneous dependencies as we go down the timesteps.
Generalizing this for timesteps :
Drawbacks of Vanilla RNN
The major drawback of the RNN architecture is that it cannot work well on sequences with Long Range Dependency, as it suffers from the well-known Vanishing Gradient Problem.
Understanding Long Range Dependency
→ Sometimes in a language, sentences are framed in such a way that they have Long Range Dependencies, which means a word which comes earlier in a sentence influences what needs to come much later in that sentence.

→ A Vanilla RNN architecture finds it difficult to memorize the context from earlier words onto words that come much later.
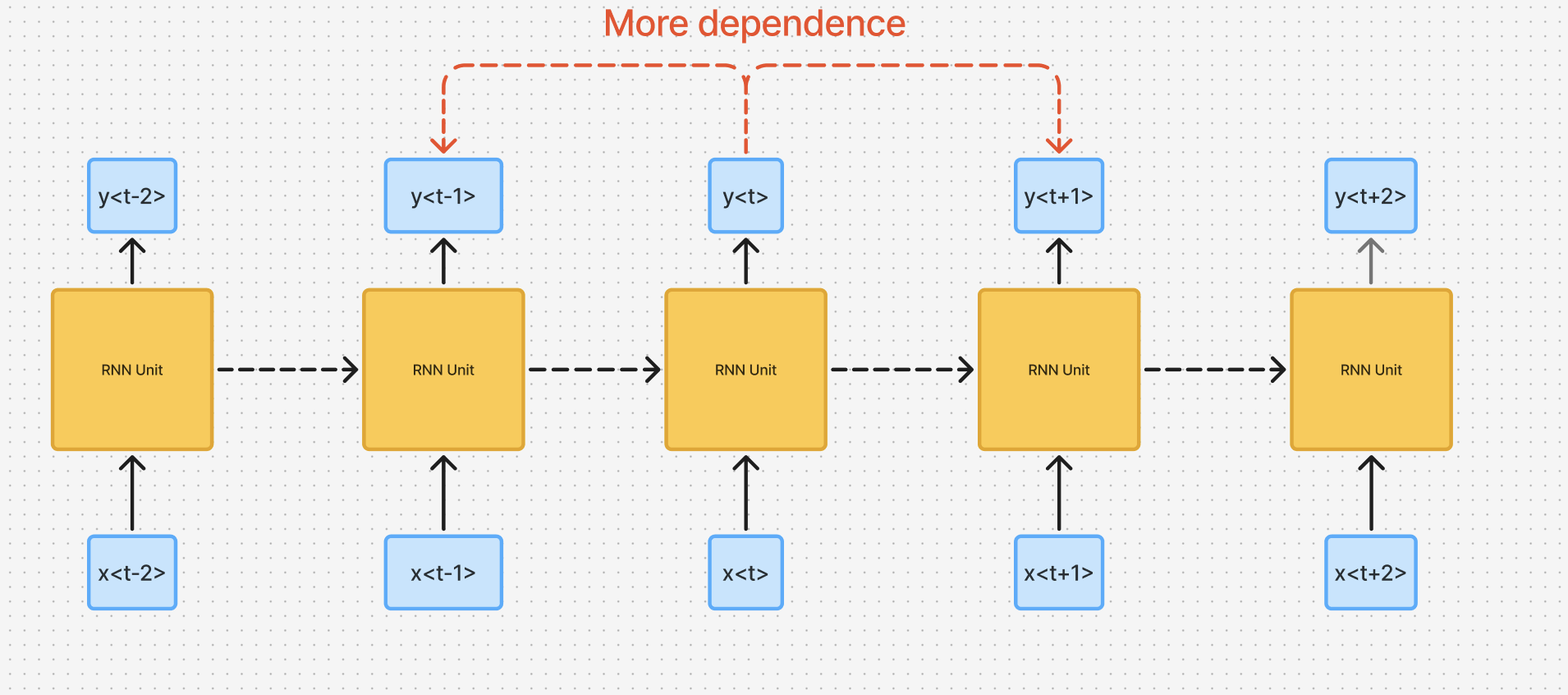
Why This Happens
- This is because in this architecture, the output at a timestep is closely associated by neighbors of and not so much by distant neighbors
The vanishing gradient problem prevents vanilla RNNs from effectively learning dependencies that span many timesteps.
Therefore in order to capture the long range context, we introduce the concept of ‘Context Cell’ or ‘Memory Cell’ which acts as an additional input to these sequential units. This forms the basis of subsequent architectures in sequential modelling namely, Gated Recurrent Unit and Long Short Term Memory.